
Retrieval Augmented Generation (RAG) bezeichnet eine Technologie, die es KI-Agenten erlaubt, auf eine externe Wissensbasis zuzugreifen, anstatt sich ausschließlich auf antrainierte Daten zu verlassen. Dies ist die Grundvoraussetzung für den produktiven Einsatz von KI im Unternehmensumfeld, da nur so interne Dokumente, Richtlinien oder spezifische Fachdaten verarbeitet werden können.
Ein zentrales Hindernis bei der Implementierung ist oft die Herkunft der verfügbaren Anleitungen und Software-Lösungen. Viele populäre Tutorials stammen aus dem US-amerikanischen Raum und vernachlässigen europäische Datenschutzstandards gänzlich. Für hiesige Unternehmen ist der Datenschutz jedoch keine optionale Zusatzleistung, sondern eine zwingende rechtliche Grundlage. Ein RAG-System muss daher gewährleisten, dass sensible Daten nicht unkontrolliert an Drittanbieter abfließen.
Zudem scheitern herkömmliche Ansätze häufig an der technischen Präzision. Sie haben Schwierigkeiten, Informationen aus komplexen Dateiformaten korrekt zu extrahieren oder Tabellenwerte logisch zu verknüpfen. Ein modernes System muss deshalb Strategien implementieren, die über reine Textsuche hinausgehen und eine zuverlässige, datenschutzkonforme Informationswiedergabe garantieren.
Der Technologie-Stack (Software und Architektur)
Um Unabhängigkeit von großen Cloud-Anbietern zu erreichen und die Datenhoheit zu behalten, setzt dieses Konzept auf eine Kombination aus leistungsfähiger Open-Source-Software und europäischen Hosting-Lösungen. Die Architektur besteht aus drei Hauptkomponenten, die vollständig auf einem eigenen Server betrieben werden können.
Das Herzstück bildet n8n als Orchestrierungstool. Hier laufen alle Fäden zusammen: Es verknüpft die verschiedenen Anwendungen, steuert die Datenflüsse und automatisiert die Prozesse. Als Benutzeroberfläche dient Open Web UI, eine Alternative zu ChatGPT, die als Frontend für die Kommunikation mit dem KI-Agenten fungiert.
Für die Speicherung der vektorisierten Daten (in Zahlenwerte umgewandelte Textinformationen) kommt Supabase zum Einsatz. Diese auf PostgreSQL basierende Datenbank verwaltet nicht nur die Vektoren, sondern speichert auch Metadaten und extrahierte Bilder. Sämtliche Komponenten werden idealerweise auf einem virtuellen privaten Server (VPS) innerhalb der EU gehostet, um die Einhaltung der DSGVO zu erleichtern.
Datenverarbeitung und Ingestion-Pipeline
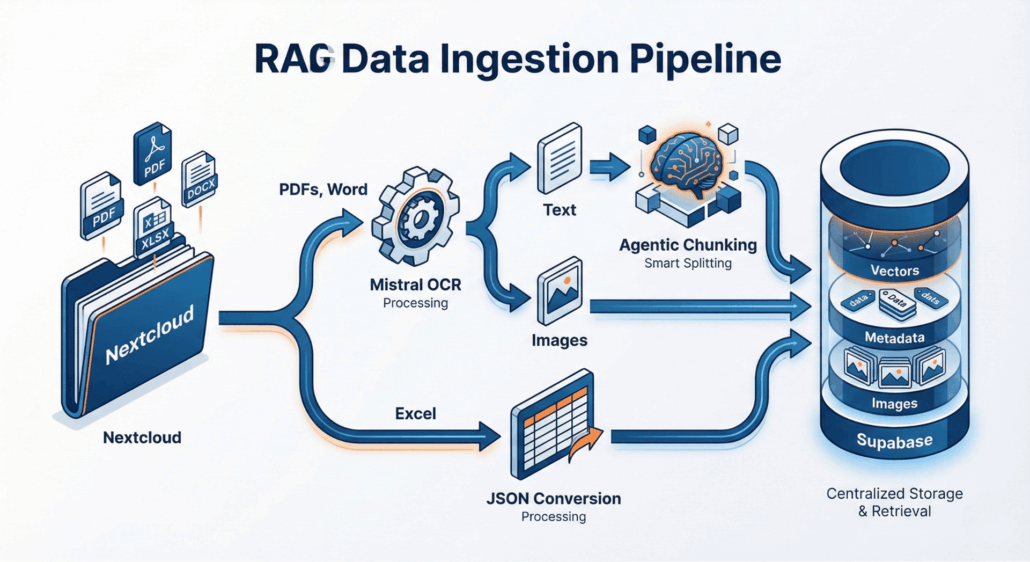
Die Qualität der Antworten eines KI-Agenten hängt maßgeblich davon ab, wie gut die Quelldaten aufbereitet werden. In diesem Setup werden Dokumente zunächst aus einem Cloud-Speicher abgerufen. Für die sichere Ablage und Synchronisation der Quelldokumente bietet sich Nextcloud Hosting auf einem deutschen Server an, da dies eine datenschutzkonforme Alternative zu US-Diensten wie Google Drive darstellt.
Ein wesentlicher Fortschritt gegenüber einfachen Systemen ist die multimodale Verarbeitung mittels Mistral OCR. Diese Technologie (Optical Character Recognition) liest nicht nur reinen Text aus PDFs, sondern erkennt, extrahiert und beschriftet auch enthaltene Bilder, wie etwa Grafiken in einer Bedienungsanleitung. Diese Bilder werden separat gespeichert und dem Agenten später per Link zur Verfügung gestellt.
Bei der Textzerlegung kommt das sogenannte Agentic Chunking zum Einsatz. Statt Texte stur nach einer festen Zeichenanzahl zu trennen, analysiert ein Sprachmodell den Inhalt und setzt die Schnittstellen dort, wo ein Gedankengang endet. Dadurch bleibt der thematische Kontext innerhalb eines Textabschnitts (Chunks) erhalten, was die spätere Auffindbarkeit massiv verbessert. Tabellarische Daten aus Excel-Dateien werden hingegen nicht als Fließtext behandelt, sondern zeilenweise in strukturierte JSON-Objekte umgewandelt, um Berechnungen zu ermöglichen.
Strategien zur Informationsabfrage (Retrieval)
Das reine Finden von Dokumenten reicht oft nicht aus, um präzise Antworten zu generieren. Daher nutzt das System Reranking-Algorithmen. Eine Vektordatenbank liefert standardmäßig die mathematisch ähnlichsten Ergebnisse zurück, was nicht immer der inhaltlich relevantesten Antwort entspricht. Ein Reranking-Modell filtert diese Roh-Ergebnisse erneut und reduziert sie auf die wenigen, tatsächlich nützlichen Treffer. Dies verhindert, dass der KI-Agent mit irrelevanten Informationen überflutet wird.
Ergänzend dazu wird der Ansatz des Agentic RAG verfolgt. Hierbei erhält der Agent Zugriff auf verschiedene Werkzeuge (Tools) und entscheidet autonom, welches er für die Beantwortung einer Frage benötigt:
- Vector Store Tool: Für allgemeine Wissensfragen basierend auf unstrukturierten Texten.
- SQL-Query Tool: Speziell für tabellarische Daten. Wenn nach Umsatzzahlen gefragt wird, führt der Agent selbstständig eine SQL-Datenbankabfrage durch, um Werte zu summieren oder zu vergleichen, anstatt sie ungenau zu schätzen.
- Full Document Scan: Sollten die Textauszüge nicht genügen, kann der Agent das gesamte Dokument anfordern.
Synchronisation und Datenaktualität
Ein RAG-System ist nur so gut wie die Aktualität seiner Datenbasis. Um manuelle Eingriffe zu vermeiden, überwacht ein automatisierter Workflow die Datenquellen im Hintergrund. In regelmäßigen Intervallen prüft das System, ob neue Dateien hinzugefügt oder bestehende bearbeitet wurden. Dies geschieht durch den Abgleich von Zeitstempeln („Last Modified“).
Werden Änderungen erkannt, stößt das System den Verarbeitungsprozess nur für die betroffenen Dateien neu an. Alte Vektoren und Metadaten werden dabei gezielt gelöscht und durch die aktualisierten Versionen ersetzt. Ebenso wichtig ist die Lösch-Routine: Entfernt ein Nutzer eine Datei aus dem Cloud-Speicher, registriert der Workflow das Fehlen der Datei beim nächsten Abgleich und bereinigt die Vektordatenbank entsprechend. So wird verhindert, dass der Agent Antworten auf Basis veralteter oder bereits gelöschter Informationen generiert.
Infrastruktur und Self-Hosting
Der Betrieb dieser Architektur auf eigener Hardware (Self-Hosting) bietet neben dem Datenschutz auch signifikante wirtschaftliche und technische Vorteile. Durch die Nutzung von Docker-Containern lassen sich Anwendungen wie n8n, Supabase und Open Web UI isoliert und sicher auf einem einzigen Server betreiben. Die Wartung und Aktualisierung der Software erfolgt dabei effizient über Befehle in der Kommandozeile.
Im Vergleich zu Cloud-Abonnements entfallen bei diesem Modell künstliche Limitierungen, wie etwa eine begrenzte Anzahl an Workflow-Ausführungen pro Monat. Unternehmen zahlen lediglich die fixen Kosten für die Server-Infrastruktur, was bei steigendem Nutzungsvolumen oft deutlich kostengünstiger ist. Zudem behält der Betreiber die vollständige Kontrolle darüber, wo die Daten physisch liegen und wer Zugriff darauf hat.



